The Stateless Reality
Understanding and building the four types of memory that Denis Rothman identifies as critical for business-ready AI. The first type…
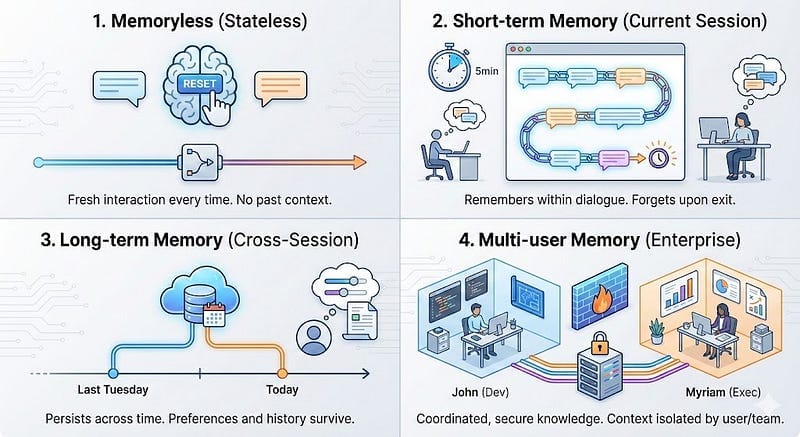
Understanding and building the four types of memory that Denis Rothman identifies as critical for business-ready AI. The first type (disussed here), is Memoryless or Stateless.
Part 1: Memoryless (Stateless) Architecture
To understand the fundamental nature of stateless Large Language Model (LLM) interactions, we must recognize that the model has no inherent memory between API calls. Every interaction is an isolated, discrete event.
For a stateless model to perform a complex task successfully, the entire necessary context (the goal, the constraints, and the background information,) must be present within the immediate request bundle. If the context is complete, the model succeeds.
Consider a scenario where a user wants campaign recommendations and provides all requirements in a single, consolidated prompt.
The Single-Shot Request
User says: “Create a campaign for widget2000 that targets enterprise IT managers. Use a professional, technical voice and determine what channels we should use.”
What goes to the model:
Because this is a single interaction, the payload sent to the API contains the system definition and the complete user context simultaneously.
messages = [
{
"role": "system",
"content": """You are an expert marketing strategist.
Given product details, target audience, and brand voice, your job is
to recommend specific marketing channels.
Output your recommendations as a concise list with brief justifications
based on the provided constraints."""
},
{
"role": "user",
# The complete context is provided in one turn
"content": """Create a campaign for widget2000 that targets
enterprise IT managers. Use a professional, technical voice
and determine what channels we should use."""
}
]
# The stateless model processes this isolated bundle and generates a responseModel response (hypothetical success): (JSON)
{
"role": "assistant",
"content": "Based on the target audience of enterprise IT managers and a professional technical voice for widget2000, I recommend: 1. LinkedIn Sponsored Content (for targeting by job title and seniority), 2. Industry-specific Technical Publications (e.g., TechCrunch, Wired for credibility), and 3. Technical Webinars (for in-depth product demonstrations)."
}Why this works in a stateless environment: This interaction is successful precisely because the immediate request bundle contained every data token necessary for the task. The model didn’t need to “remember” anything from a previous turn because the product (widget2000), audience (enterprise IT managers), and voice (professional, technical) were all present in the current input.
When Stateless Is Intentional
This memoryless pattern is not a limitation; rather, it’s deliberately chosen for scenarios requiring isolated, unbiased analysis:
- A/B testing: Each variant must be evaluated independently; context from other variants would contaminate the results.
- Independent document analysis: Each document should be reviewed on its own merits, not influenced by previously analyzed documents.
- High-stakes decisions: Financial approvals or medical diagnoses where historical bias could compromise objectivity.
- Privacy-sensitive scenarios: Each user interaction should be isolated, with no data leakage from previous users.
In these cases, stateless architecture is a feature that prevents unwanted context bleeding.
Where the Architecture Problem Occurs
The architecture problem arises when this consolidated information must be gathered across multiple turns over time, and the application fails to persist state between those turns.
In a multi-turn scenario without state management, the application architecture lacks a shared state mechanism between independent request/response cycles. If the application layer fails to manually re-aggregate previous turns into a consolidated view (like the successful example above) for every new request, the model processes the latest prompt in total isolation, with no access to data tokens from previous transactions.
Example of architectural failure:
# Turn 1 (Monday morning)
response_1 = model.generate([
{"role": "user", "content": "Campaign for widget2000 targeting IT managers"}
])
# Session ends, context discarded
# Turn 2 (Monday afternoon, new session, no state persistence)
response_2 = model.generate([
{"role": "user", "content": "What channels should we use?"}
])
# Model has no access to widget2000 or IT managers from Turn 1The Engineering Challenge
This architectural necessity of supplying complete context for every API call is why simple demos can fail in complex production environments:
Demos work because:
- Single session, developer manually maintains conversation history
- Context accumulation happens in memory during development
- Session boundaries never tested
Production breaks because:
- Users log out, browsers close, servers restart
- New instances spin up with no access to previous context
- State exists nowhere unless explicitly persisted
To manage context over time effectively, production systems require engineered persistence solutions built around the stateless model.
Denis Rothman’s 2024 book Building Business-Ready Generative AI Systems addresses this with a sophisticated architecture that moves beyond simple conversational history buffers[¹]. His framework identifies four distinct types of memory required for robust applications — and most importantly, when to implement each one.
Coming in Part 2: Short-term Memory (Current Session)
We’ve seen that stateless architecture works perfectly when all context arrives in a single prompt. But what happens when users naturally converse: asking follow-up questions, refining requirements, building understanding through dialogue?
User: "Campaign for widget2000"
System: "What's your audience?"
User: "IT managers"How do you make the third exchange remember both widget2000 AND IT managers without manually tracking conversation state in your application code?
Part 2 reveals the application architecture pattern that bridges independent API calls into coherent conversations. We’ll examine exactly what data structures maintain state, how token costs scale with conversation length, and why this pattern still fails the moment a user closes their browser.
Footnote/Endnote:
[¹]: Rothman, Denis. Building Business-Ready Generative AI Systems: Build Human-Centered AI Systems with Context Engineering, Agents, Memory, and LLMs for Enterprise. Packt Publishing, 2024.